The truth is, once I had a rough design for a Git-alike content store, the main challenges were all implementation details and attention to backward-compatibility (I had to add the new versioning system incrementally without any downtime in the editing tools or - God forbid - for site users). The simplicity owed a lot to the Git storage model (storing versions of entities labeled by their SHA-1 hash), which aligns neatly with the way App Engine’s High Replication Datastore likes to store and access data. There were just a few issues to work out, and I’ll list them here.
< architecture >
The simplest way to implement a Git-like store in App Engine is to create a db/ndb Model class for the object you’d like to store with the properties you’d like to store and a method for creating new revisions of that model. Unlike traditional entities which are overwritten whenever a change is made, in this case you create a completely new entity (a “revision”) on every change. This might sound wasteful compared to storing diffs, but the invariant that revisions are immutable makes the implementation easier and enables easy caching of revisions. This is one example where we rely on App Engine’s scalability to make our lives easier, and compared to the hundreds of millions of user-generated data items, the number of entities here will be relatively small. If this keeps you up at night you can always prune orphaned revisions later.
One decision we made fairly early on was to keep editing models (revisions) separate from the live models that the site uses. The primary reason for this was that we had live entities already (Video and Exercise), and finding all the places where we fetch them by key would have been an onerous and error-prone task. This choice turned out to have some other advantages as well. So the inheritance tree looks like this:

BaseVideo is a plain Python class that store the common DB properties and methods between the editing version (VideoRevision) and the run-time published version (Video). Common functionality for working with live content and revisions is in VersionedContent and BaseRevision, respectively. In our case, we could not make BaseVideo a PolyModel (as that would have changed the kind and therefore invalidate all the existing keys) so we had to introduce a metaclass to allow the subclasses to share DB properties. This enables us to add properties to VersionedContent and BaseRevision that will be inherited by subclasses. I will use Video/VideoRevision as my examples from now on, but everything stated applies equally to our other content types.
As in Git, the (key) ID of the VideoRevision is a hex-encoded SHA-1 hash of the contents of the object, which in this case is a JSON representation of the entity’s fields. There is also a string property which references the Video’s key ID, so we can track history and keep references to an object across revisions. When we create a VideoRevision for a new video, we generate a random ID, ensuring that a new Video entity will be created at publish time. Note that there may be many VideoRevision entities for a single video (tracking historical changes) but there is only ever one Video entity, preserving the current ability of published entities to reference each other by datastore key. The Video also contains the key ID of its latest VideoRevision that has been published; that is, the fields of both should be the same.
This means that to find the latest revision of an object, we need a table of content ID → revision ID. This is the “stage” (or sandbox), which represents the current editing state.
So, to make an edit to an object:
This is what the whole setup looks like after a commit:
And here is what it looks like after a second commit, where three of the four entities have been changed:
As in Git, the (key) ID of the VideoRevision is a hex-encoded SHA-1 hash of the contents of the object, which in this case is a JSON representation of the entity’s fields. There is also a string property which references the Video’s key ID, so we can track history and keep references to an object across revisions. When we create a VideoRevision for a new video, we generate a random ID, ensuring that a new Video entity will be created at publish time. Note that there may be many VideoRevision entities for a single video (tracking historical changes) but there is only ever one Video entity, preserving the current ability of published entities to reference each other by datastore key. The Video also contains the key ID of its latest VideoRevision that has been published; that is, the fields of both should be the same.
This means that to find the latest revision of an object, we need a table of content ID → revision ID. This is the “stage” (or sandbox), which represents the current editing state.
So, to make an edit to an object:
- Look up the latest edit version of the object in the stage (this is a get-by-key, which is very efficient)
- Apply the requested changes
- Compute a new revision ID from the updated properties
- Create the new revision entity with the revision ID as its key ID and put it into the datastore
- Update the stage to point to the new revision ID
This is what the whole setup looks like after a commit:
And here is what it looks like after a second commit, where three of the four entities have been changed:
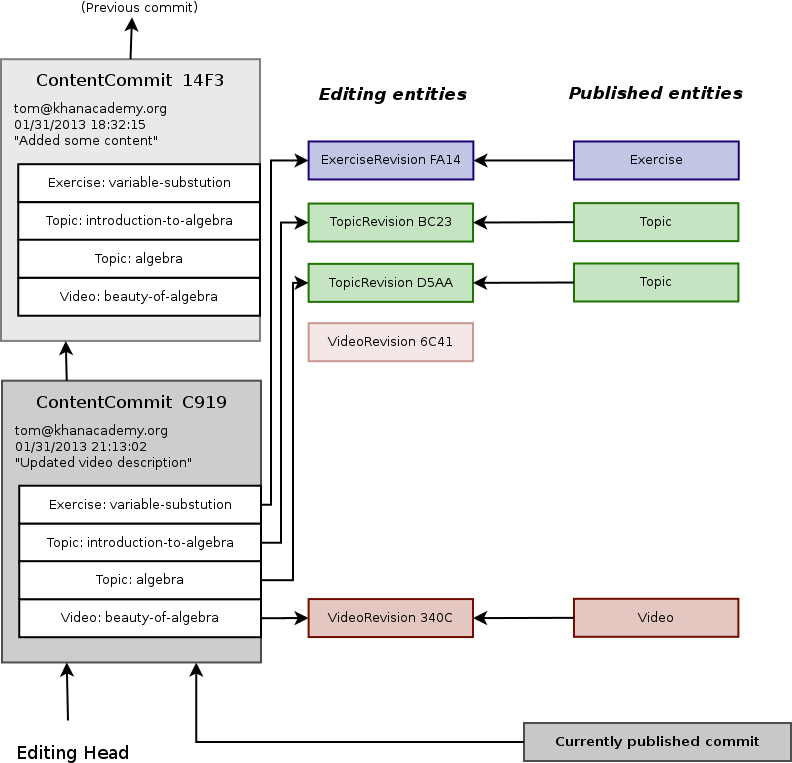
Having the snapshot and commits be tables of revision IDs means that doing a diff is very efficient: just look for entries that differ between the two tables, fetch only those revisions, and diff their properties. This makes it easy to recompute values or invalidate caches based on just the content that has changed without having to compare old and new properties for every piece of content.
< publishing >
At its core, publishing a commit to the site involves identifying which content revisions have changed (by comparing the revision IDs in the commits’ tables), fetching those revisions, and copying their fields onto the corresponding live entities, creating any entities that don’t already exist. Then the “currently published commit” setting is updated, which instantaneously changes the version of the entities that all the user-facing handlers look at when rendering the site, and you’re done. The process works equally well for rolling back to an earlier commit.
Publishing is also a great place for denormalizing data. Since Video and VideoRevision are separate models, we can add properties to just Video (such as the canonical URL) that are calculated and saved on the entity during publish. We can also pre-warm some caches that are invalidated on each publish, so that users never see a cache miss.
Separating live entities from editing entities does add some complexity to the system, but after publish we can now reference a Video by its key (which is stable) or we can run datastore queries on its indexed fields, neither of which we could have done with just the revisions.
< sync / merge >
Because of the simplicity of the versioning system, if I want to import the latest copy of the topic tree to my local dev datastore, all I need to do is:
- Download the latest commit from the live site,
- Make a list of the revision entities that I don’t have,
- Download the revisions in bulk and push them directly into my datastore
- Set the downloaded commit as the “head” commit
It is possible that the commit that has been synced is not a descendant of the local head commit (there have been changes both locally and remotely since the last sync). In this case we can create a “merge” commit which finds the common ancestor and then performs an automatic three-way merge between them. The algorithm is trivial when no entity has been modified in both branches, but it’s still possible do a field-by-field merge, which should cover a majority of cases. This allows us to copy all our content to a new datastore, make some changes, publish and preview them, and then merge those changes back to the live site automatically.
< tl;dr >
I wanted to go into some detail to give you an idea of the design decisions and trade-offs we made on the road to having a flexible, extensible versioning system that works efficiently on App Engine. Some of these decisions are specific to our particular situation, but a lot of these ideas could be generally useful in building a CMS on a NoSQL-type platform like Google’s.
If you find yourself using these patterns please drop me a line and let me know how it’s working for you.